
Model Labels
For an AI model to be trusted the motives behind its design and its fitness for purpose need to be made transparent
This is best achieved by publishing model statements. For example:
This is best achieved by publishing model statements. For example:
PRIDAR: Prioritising AI Risk Model
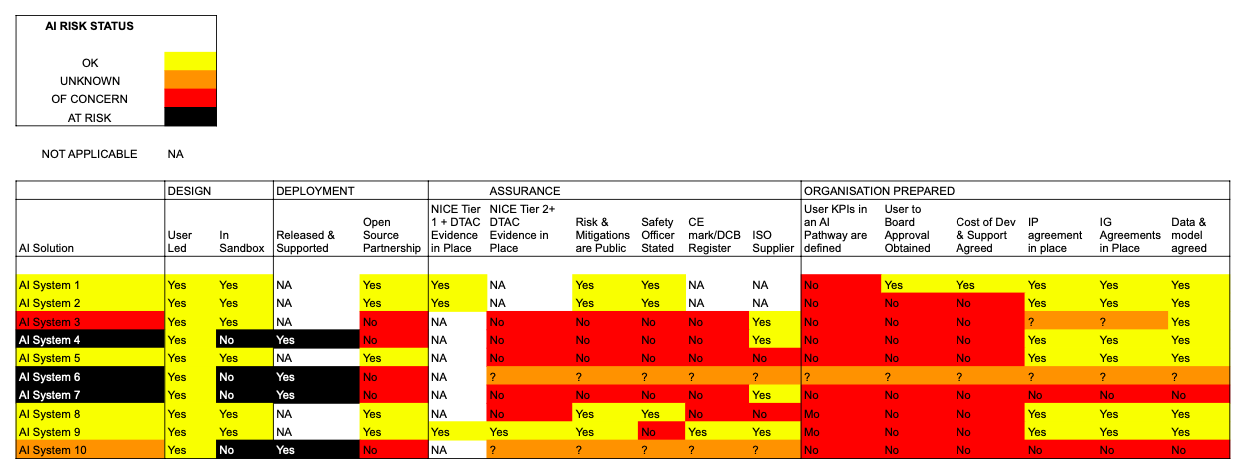
AN EXAMPLE OF PRIDAR IN A HEALTHCARE SETTING.
Motivation
PRIDAR was created to enable Senior Management Teams to visualise the risk associated with the AI models embodied the systems they have access to.
Current ML/AI Model Label Reference Number: PRIDAR2
Version control:
Version 1 Automatic Visualisation of Risk
Version 2 Risk Visualisation Framework (Without Predictions seen above)
Release Terms: Version 1, Version 2
Outcome: prioritisation of a systems risk occasioned by planned or implemented AI
Output: a risk ranking for an AI enabled system via a web user interface
Output to Trigger: risk mitigation at a Board Level
Target Population: Corporate Development Teams
Time of Prediction: immediate based on model feedback
Input data source: model feedback from the public, users, and suppliers
Input data type: text and json from compliance reports
Training details: projects arising with a senior management teams and investment houses
Model type: Bayesian Ranking of risk (excluded in Version 2) based on NLP analysis of evidence.
Motivation
PRIDAR was created to enable Senior Management Teams to visualise the risk associated with the AI models embodied the systems they have access to.
Current ML/AI Model Label Reference Number: PRIDAR2
Version control:
Version 1 Automatic Visualisation of Risk
Version 2 Risk Visualisation Framework (Without Predictions seen above)
Release Terms: Version 1, Version 2
Outcome: prioritisation of a systems risk occasioned by planned or implemented AI
Output: a risk ranking for an AI enabled system via a web user interface
Output to Trigger: risk mitigation at a Board Level
Target Population: Corporate Development Teams
Time of Prediction: immediate based on model feedback
Input data source: model feedback from the public, users, and suppliers
Input data type: text and json from compliance reports
Training details: projects arising with a senior management teams and investment houses
Model type: Bayesian Ranking of risk (excluded in Version 2) based on NLP analysis of evidence.
SISDA: THE SUICIDAL IDEATION MODEL

Motivation
Between 5 and 10% of people who reach out to mental health care providers suffer with suicidal thoughts and feelings, and express these in their electronic submissions for help. Care Providers confirm that 88% of patients that express such thoughts and feelings, subsequently attempt suicide weeks after a presentation. Care services confirm that responding to suicidal ideation in speech within 48 hours is good practice. Care providers also report that this can take one person, one day a week to complete, per care service. There is subsequently a motivation to have clinicians automatically alerted to the existence of potential suicidal language in mental health submissions. SISDA was developed to achieve this aim. It is currently used in the NHS, and US Care providers who operate in acute and none acute mental health settings.
Current ML/AI Model Reference Number: SISDA2
Version Control: Version 1 - Cardiff University Research, Version 2 - SISDA Validation & Alignment
Release Terms: Version 1-2
Outcome: Identification of suicidal ideation in online text
Output: 97% likelihood of person needing to be quickly referred to a clinician for triage
Output to Trigger: a person being engaged more quickly by a mental health clinician (e.g. less that 48 hours)
Target Population: people that seek to triage people seeking mental health and wellbeing support using online data capture tools
Time of Prediction: Less than 1 second, (Depending on pattern matching)
Input data source: Online forms, Speech to Text translations
Input data type: Free text containing more that 4 words
Training details: Data in the form of Short form SMS and content Validated by Social Scientists and Mental Health Clinicians
Model type: Term Frequency/Inverse Document frequency. NLP targets: precision of 69.31%, recall of 72.9 % and accuracy of 72.8%.
True Positive Target post alignment work with clinicians = 97% per 1000 text submissions.
Validation: The original model was validated via research undertake by Cardiff University research. The TD-IFD model is subsequently maintained by system audits analysis per 1000 instances of use and alignment research undertaken by local clinical users. From 2023, evidence was gathered in line with BS 30440. The Standard for the Validation of AI in Healthcare, The EU AI Act, and the NIST RMF.
Between 5 and 10% of people who reach out to mental health care providers suffer with suicidal thoughts and feelings, and express these in their electronic submissions for help. Care Providers confirm that 88% of patients that express such thoughts and feelings, subsequently attempt suicide weeks after a presentation. Care services confirm that responding to suicidal ideation in speech within 48 hours is good practice. Care providers also report that this can take one person, one day a week to complete, per care service. There is subsequently a motivation to have clinicians automatically alerted to the existence of potential suicidal language in mental health submissions. SISDA was developed to achieve this aim. It is currently used in the NHS, and US Care providers who operate in acute and none acute mental health settings.
Current ML/AI Model Reference Number: SISDA2
Version Control: Version 1 - Cardiff University Research, Version 2 - SISDA Validation & Alignment
Release Terms: Version 1-2
Outcome: Identification of suicidal ideation in online text
Output: 97% likelihood of person needing to be quickly referred to a clinician for triage
Output to Trigger: a person being engaged more quickly by a mental health clinician (e.g. less that 48 hours)
Target Population: people that seek to triage people seeking mental health and wellbeing support using online data capture tools
Time of Prediction: Less than 1 second, (Depending on pattern matching)
Input data source: Online forms, Speech to Text translations
Input data type: Free text containing more that 4 words
Training details: Data in the form of Short form SMS and content Validated by Social Scientists and Mental Health Clinicians
Model type: Term Frequency/Inverse Document frequency. NLP targets: precision of 69.31%, recall of 72.9 % and accuracy of 72.8%.
True Positive Target post alignment work with clinicians = 97% per 1000 text submissions.
Validation: The original model was validated via research undertake by Cardiff University research. The TD-IFD model is subsequently maintained by system audits analysis per 1000 instances of use and alignment research undertaken by local clinical users. From 2023, evidence was gathered in line with BS 30440. The Standard for the Validation of AI in Healthcare, The EU AI Act, and the NIST RMF.
EMPDAR: MOTIVATIONAL INTERVIEWING COMPLIANCE MODEL

|
Motivation
Clinicians and therapists are increasingly being asked to counsel people in difficult situations remotely because of restrictions around one-to-one meetings. Staff are being subsequently trained in motivational interviewing techniques. Much of this training is delivered remotely via 'watch and learn' video sessions, or via role-play between tutors and staff attending training. One aspect of motivational interviewing is to evidence that you have heard what matters to the subject of a counselling session by feeding back what you believe you have heard. The frequency with which this occurs is a signal of the degree of empathy a clinician or therapist has evidence, as is the matching of the speed with which two parties speak. To enable more people to receive interview training a model was needed to measure empathy engendered during training sessions.
Current ML/AI Model Label Reference Number: EMPDAR1, EMPDAR2
Version Control: Version 1 Meet Insight BBC Project, Version 2 - Independent Research
Release Terms: Version 1&2
Outcome: Identification of empathy in two-party dialogue
Output: the degree to which two parties mirror and match each other’s language and speaking rate
Output to trigger: a person evidencing compliance to a training standard
Target Population: system providers and trainers responsible for motivational interviewing
Time of Prediction: 33 seconds after a training session is uploaded for analysis
Input data source: call recordings
Input data type: wav, mp3 files
Training details: sound recordings of two parties in role play
Model type: LTSM on speech timings, and topic modelling
Clinicians and therapists are increasingly being asked to counsel people in difficult situations remotely because of restrictions around one-to-one meetings. Staff are being subsequently trained in motivational interviewing techniques. Much of this training is delivered remotely via 'watch and learn' video sessions, or via role-play between tutors and staff attending training. One aspect of motivational interviewing is to evidence that you have heard what matters to the subject of a counselling session by feeding back what you believe you have heard. The frequency with which this occurs is a signal of the degree of empathy a clinician or therapist has evidence, as is the matching of the speed with which two parties speak. To enable more people to receive interview training a model was needed to measure empathy engendered during training sessions.
Current ML/AI Model Label Reference Number: EMPDAR1, EMPDAR2
Version Control: Version 1 Meet Insight BBC Project, Version 2 - Independent Research
Release Terms: Version 1&2
Outcome: Identification of empathy in two-party dialogue
Output: the degree to which two parties mirror and match each other’s language and speaking rate
Output to trigger: a person evidencing compliance to a training standard
Target Population: system providers and trainers responsible for motivational interviewing
Time of Prediction: 33 seconds after a training session is uploaded for analysis
Input data source: call recordings
Input data type: wav, mp3 files
Training details: sound recordings of two parties in role play
Model type: LTSM on speech timings, and topic modelling
ARDAR: THE CALLER BREATHING RATE MODEL

Motivation
A model was needed that would enable the host of call handling services to recognise breathlessness in call recordings. ARDAR was first used to prove that one could differentiate between callers with normal and acute respiratory distress breathing. It was subsequently used to differentiate between phrases spoken by people with sputum colours, wellbeing rates, and MRC Dyspnoea scores that were normal, and those whose conditions had deteriorated by 99.7% for 5 days.
Current ML /AI Model Label Reference Number: ARDAR2
Version Control: Version 1 - Welsh Ambulance
Release Terms: Version 1 for research purposes
Outcome: Identification of breathlessness that would trigger a request to attend an Emergency Department
Output: % likelihood of a person needing to be quickly referred to a clinician for triage (Depending on telephony system)
Output to trigger: a person being engaged more quickly by a call handler
Target Population: systems that seek to triage people with an existing or potential lung disease
Time of Prediction: Less than 1 second, (Depending on the deployment of a containerised model within a call handling system or phone)
Input data source: Pre-processed speech in the form of call recordings or live feeds
Input data type: de-identified sound data
Training details: Call recordings validated by 111 call managers relating to people that required an ambulance because of breathing difficulties and those that required an ambulance for other reasons, 120 days of call recordings/self-reported breathlessness data provided by 35 people with positive PCR tests
Model type: a Logistic Regression and Mel Frequency Cepstral Coefficients model
A model was needed that would enable the host of call handling services to recognise breathlessness in call recordings. ARDAR was first used to prove that one could differentiate between callers with normal and acute respiratory distress breathing. It was subsequently used to differentiate between phrases spoken by people with sputum colours, wellbeing rates, and MRC Dyspnoea scores that were normal, and those whose conditions had deteriorated by 99.7% for 5 days.
Current ML /AI Model Label Reference Number: ARDAR2
Version Control: Version 1 - Welsh Ambulance
Release Terms: Version 1 for research purposes
Outcome: Identification of breathlessness that would trigger a request to attend an Emergency Department
Output: % likelihood of a person needing to be quickly referred to a clinician for triage (Depending on telephony system)
Output to trigger: a person being engaged more quickly by a call handler
Target Population: systems that seek to triage people with an existing or potential lung disease
Time of Prediction: Less than 1 second, (Depending on the deployment of a containerised model within a call handling system or phone)
Input data source: Pre-processed speech in the form of call recordings or live feeds
Input data type: de-identified sound data
Training details: Call recordings validated by 111 call managers relating to people that required an ambulance because of breathing difficulties and those that required an ambulance for other reasons, 120 days of call recordings/self-reported breathlessness data provided by 35 people with positive PCR tests
Model type: a Logistic Regression and Mel Frequency Cepstral Coefficients model
WELLDAR: COPD DATA MODEL

Motivation
People that are expected to experience poor wellbeing i.e. COPD patients suffer greatly during exacerbations are often associated with emergency admissions. If a person were able to predict when an exacerbation is likely to occur then they, and primary care services, could better manage exacerbations outside of an emergency setting. To understand if this was possible a tool had to be designed. WELLDAR enables people to visualise their wellbeing data with clinical scores, and share this data with a Senior Responsible Officers (SROs). The aim being that SROs, in line with ICO regulations and the necessary consents, aggregate on device findings to build classifiers (e.g ARDAR, and share it without prejudicing the identity of individuals e.g. Wellbeing Maps)
Current Data Model Reference Number: WELLDAR2 and WELLDAR3
Version Control: Version 1 & 2 Independent Reseaarch
Release Terms: Version 1 and 2
Outcome: de-identified data, protected by local differential privacy, on device testing of models, model error reporting
Output: ethically collected data that could be used to predict the need for human intervention
Output to Trigger: a researcher / data scientist being able to use ethical data to build care models
Target Population: mobile phone users with COPD
Time of Prediction: Less than 30 seconds on device
Input data source: on device sensors and forms
Input data type: steps, free text, speech
Training details: on device classifiers for speech rate trained with RASA
Model type: privacy protecting federated machine learning
People that are expected to experience poor wellbeing i.e. COPD patients suffer greatly during exacerbations are often associated with emergency admissions. If a person were able to predict when an exacerbation is likely to occur then they, and primary care services, could better manage exacerbations outside of an emergency setting. To understand if this was possible a tool had to be designed. WELLDAR enables people to visualise their wellbeing data with clinical scores, and share this data with a Senior Responsible Officers (SROs). The aim being that SROs, in line with ICO regulations and the necessary consents, aggregate on device findings to build classifiers (e.g ARDAR, and share it without prejudicing the identity of individuals e.g. Wellbeing Maps)
Current Data Model Reference Number: WELLDAR2 and WELLDAR3
Version Control: Version 1 & 2 Independent Reseaarch
Release Terms: Version 1 and 2
Outcome: de-identified data, protected by local differential privacy, on device testing of models, model error reporting
Output: ethically collected data that could be used to predict the need for human intervention
Output to Trigger: a researcher / data scientist being able to use ethical data to build care models
Target Population: mobile phone users with COPD
Time of Prediction: Less than 30 seconds on device
Input data source: on device sensors and forms
Input data type: steps, free text, speech
Training details: on device classifiers for speech rate trained with RASA
Model type: privacy protecting federated machine learning
CAREDAR: WELLBEING DATA MODEL

Motivation
Family members and extended family members bear 90% of the social care burden in the UK. When such people become full-time unpaid carers their stress levels rise, and wellbeing can be negatively effected. This situation was exacerbated during COVID lockdowns in 2020, new full time carers frequently presented to their GP within 6 months of taking their new role with mental health and physical health issues relating to stress and loneliness. A carers group recognised that the most effective way of reducing stress and improving wellbeing was to network carers together and to nudge them to walk and socialise more. A model was needed that could be deployed on carers mobile phones that would protect their privacy, learn about what activity and movement levels generated good self-reported well-being scores and identify the most effective time to nudge carers to walk and socialise.
Current ML / AI Model Label Reference Number: CAREDAR2
Versions: Version 1 - Independent Research
Release Terms: Version1 , Version 2
Outcome: identify when a carer’s wellbeing could be improved by activity and socialisation, and enable carers to publish their wellbeing
Output: an in-app message suggesting carers share their status with fellow carers
Output to Trigger: a person engaging another person on issues that matter to them
Target Population: full-time carers with a mobile phone
Time of Prediction: it takes 3 weeks to establish a ground truth for optimal well being related to movement and social contact
Input data source: self-reported network contact, and a phone pedometer, and locally differential private wellbeing reports
Input data type: messages sent to network contacts, self reported wellbeing scores, and steps
Training details: 93 Carers Trust members with CareCare (the model manifested in an app design) reporting on the fitness for purpose of in-app nudges
Model type: an on device Logistic Regression model that updates global models using local differential privacy data and federated machine learning.
Family members and extended family members bear 90% of the social care burden in the UK. When such people become full-time unpaid carers their stress levels rise, and wellbeing can be negatively effected. This situation was exacerbated during COVID lockdowns in 2020, new full time carers frequently presented to their GP within 6 months of taking their new role with mental health and physical health issues relating to stress and loneliness. A carers group recognised that the most effective way of reducing stress and improving wellbeing was to network carers together and to nudge them to walk and socialise more. A model was needed that could be deployed on carers mobile phones that would protect their privacy, learn about what activity and movement levels generated good self-reported well-being scores and identify the most effective time to nudge carers to walk and socialise.
Current ML / AI Model Label Reference Number: CAREDAR2
Versions: Version 1 - Independent Research
Release Terms: Version1 , Version 2
Outcome: identify when a carer’s wellbeing could be improved by activity and socialisation, and enable carers to publish their wellbeing
Output: an in-app message suggesting carers share their status with fellow carers
Output to Trigger: a person engaging another person on issues that matter to them
Target Population: full-time carers with a mobile phone
Time of Prediction: it takes 3 weeks to establish a ground truth for optimal well being related to movement and social contact
Input data source: self-reported network contact, and a phone pedometer, and locally differential private wellbeing reports
Input data type: messages sent to network contacts, self reported wellbeing scores, and steps
Training details: 93 Carers Trust members with CareCare (the model manifested in an app design) reporting on the fitness for purpose of in-app nudges
Model type: an on device Logistic Regression model that updates global models using local differential privacy data and federated machine learning.
SKINDAR: SKIN DATA MODEL
Motivation
There is a national shortage of Dermatologists. The end result is that when GPs take digital photographs of suspected tumours so they can email them to a dermatologist for assessment they wait for a very long time to get feedback. To reduce the time to get feedback many organisations are attempting to build classifiers that can automatically identify cancer type. The problem that exists is that there is not a national annotated database of cancer images-gathered using mobile phone devices. So CarefulAI and students from UCL IXN developed a method of gathering such data into a pipeline that could feed classifier development in the NHS.
Current ML/AI Model Label Reference Number: SKINDAR2
Version control: Version 1 & 2 Independent Research
Release Terms: Version 1 - 2
Outcome: human annotated digital images for use in classifier development
Output: an android app that enables images to be gathered annotated an shared with an online repository
Output to Trigger: the development of image classifiers by academic researchers
Target Population: UK
Time of Prediction: once an image is captured clinicians can annotate an image in 15 seconds
Input data source: mobile phone photographs
Input data type: png, jpeg, 4-12MP, with annotation in the file name
Training details: human annotated images
Model type: annotated images suitable for Canny-Deriche type algorithm models
There is a national shortage of Dermatologists. The end result is that when GPs take digital photographs of suspected tumours so they can email them to a dermatologist for assessment they wait for a very long time to get feedback. To reduce the time to get feedback many organisations are attempting to build classifiers that can automatically identify cancer type. The problem that exists is that there is not a national annotated database of cancer images-gathered using mobile phone devices. So CarefulAI and students from UCL IXN developed a method of gathering such data into a pipeline that could feed classifier development in the NHS.
Current ML/AI Model Label Reference Number: SKINDAR2
Version control: Version 1 & 2 Independent Research
Release Terms: Version 1 - 2
Outcome: human annotated digital images for use in classifier development
Output: an android app that enables images to be gathered annotated an shared with an online repository
Output to Trigger: the development of image classifiers by academic researchers
Target Population: UK
Time of Prediction: once an image is captured clinicians can annotate an image in 15 seconds
Input data source: mobile phone photographs
Input data type: png, jpeg, 4-12MP, with annotation in the file name
Training details: human annotated images
Model type: annotated images suitable for Canny-Deriche type algorithm models