
CarefulAI Assurance of Language Model Safety (CALMS)
- Reducing Harms by Embedding CALMS within GPT Based Solutions -
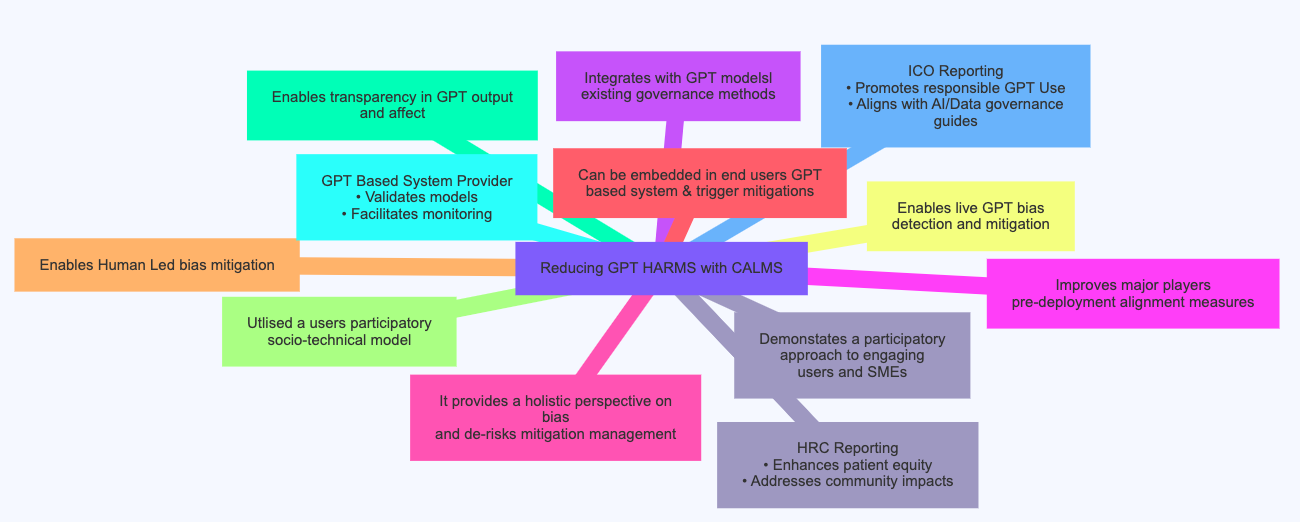
CLAMS is novel insofar as it makes continuous use of feedback from foundation model users about harms, risk, impact and severity occasioned by model use, assurance and governance.
The method by which we reduce harms with CALMS is summarised in the following process
The method by which we reduce harms with CALMS is summarised in the following process
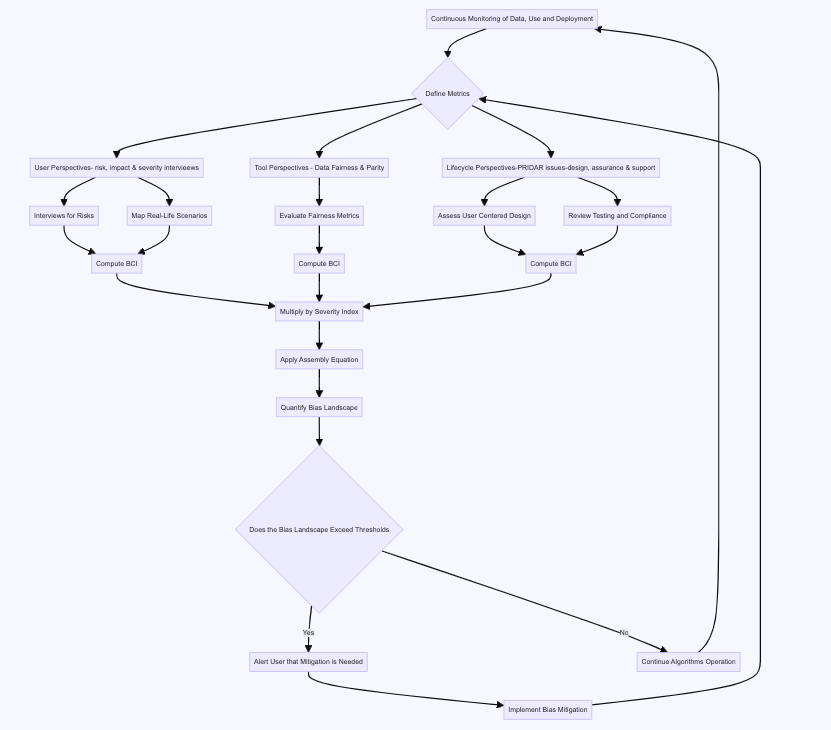
Background on CALMS
Focusing Model Bias Mitigation: A Socio-Technical Solution to Risk
The main risks associated with Foundation Models like large language models is that they can result in harm to people. Concern over harm primarily relates to how such models are used to predict outcomes or classifications that relate to a persons life e.g. their health insurance premium, or access to healthcare.
CALMS takes a socio-technical approach to identification to bias measurement as recommended by NIST. It integrates custom context-specific, subject matter, and model life user cycle bias metrics via the Assembly Equation. It also uses a privacy and security by design methodology proposed by the ICO (local differential privacy), ensuring confidential information and access control principles are adhered to in the gathering of feedback from humans.
It enables Data Protection Impact Assessment and Risk Mitigations to be triggered automatically, thus reducing potential illegal discrimination (as defined in by UK Equality legislation).
CALMS takes a socio-technical approach to identification to bias measurement as recommended by NIST. It integrates custom context-specific, subject matter, and model life user cycle bias metrics via the Assembly Equation. It also uses a privacy and security by design methodology proposed by the ICO (local differential privacy), ensuring confidential information and access control principles are adhered to in the gathering of feedback from humans.
It enables Data Protection Impact Assessment and Risk Mitigations to be triggered automatically, thus reducing potential illegal discrimination (as defined in by UK Equality legislation).
Background
With Foundation Models (e.g. LLMs) one needs to have new ways for
Because foundational models:
With Foundation Models (e.g. LLMs) one needs to have new ways for
- focussing bias mitigation
- ongoing monitoring and evaluation
- custom context-specific bias metrics
- engagement with subject matter experts
Because foundational models:
- Exhibit unstable performance: as nobody can explain why the foundation models hallucinate and therefore not advised for import decisions. Even though GPTS have been released. This is still an important limitation identified by GPT alignment teams.
- Depend on real world feedback for safety: foundation models are never released without a constant feedback loop, because the hallucinate. This loop involves users and beneficiaries of the model who rate models for their accuracy and affect. CALMS adds to this by integration human feedback relating to harms, risk, impact and severity for each interation.
A Complexity Score To Better Focus Mitigation of Bias
Integrating context specific biases, with subject matter and life cycle feedback forms a complex metric.
It is proposed the integration of these forms of bias metrics is best achieved using the Assembly Equation adapted to be relevant for use in algorithmic fairness. This involves accommodating he complexity of bias and projected affect in an algorithm, the total number of statistical and human identified bias dimensions within the algorithm, the complexity of individual biases. The frequency with which bias and affect occur in an algorithms output, relative to the total number of biases.
It is proposed the integration of these forms of bias metrics is best achieved using the Assembly Equation adapted to be relevant for use in algorithmic fairness. This involves accommodating he complexity of bias and projected affect in an algorithm, the total number of statistical and human identified bias dimensions within the algorithm, the complexity of individual biases. The frequency with which bias and affect occur in an algorithms output, relative to the total number of biases.
The Adapted Assembly equation
OB = { [∑(i=1 to N) e^(bci * ((fi - 1) / FTB))]social
+[∑(i=1 to N) e^(bci * ((fi - 1) / FTB))]technical
+[∑(i=1 to N) e^(bci * ((fi - 1) / FTB))]policy}/3
can be adapted as follows.
Where:
OB: Represents the overall bias complexity of the algorithm.
N: The total number of identified bias dimensions within the algorithm.
bci: The bias complexity index for the i-th type of bias.
fi: The frequency of the i-th type of bias in the algorithm’s output.
FTB: The total frequency count of all bias occurrences.
e: Euler's number.
OB = { [∑(i=1 to N) e^(bci * ((fi - 1) / FTB))]social
+[∑(i=1 to N) e^(bci * ((fi - 1) / FTB))]technical
+[∑(i=1 to N) e^(bci * ((fi - 1) / FTB))]policy}/3
can be adapted as follows.
Where:
OB: Represents the overall bias complexity of the algorithm.
N: The total number of identified bias dimensions within the algorithm.
bci: The bias complexity index for the i-th type of bias.
fi: The frequency of the i-th type of bias in the algorithm’s output.
FTB: The total frequency count of all bias occurrences.
e: Euler's number.
Interpretation and Application of the Assembly Equation:
Limitations and Considerations of the Assembly Equation:
- Measuring Bias Complexity: This equation quantifies not just the presence of bias but its complexity and prevalence. A higher value of BM suggests a more complex and prevalent bias structure within the algorithm. For example, in Healthcare complexity relates to number of dependencies associated with a bias e.g. a anxiety could be said to have 7 (GAD7) and depression could be said to have 9 (PHQ9)
- Dynamic Tracking: By applying this equation over time or across different versions of the algorithm, changes in bias complexity can be quantified, helping in understanding the impact of modifications or training on the bias landscape.
- Multi-Dimensional Analysis: The equation considers multiple types of biases, offering a more comprehensive view than methods that focus on a single bias type.
Limitations and Considerations of the Assembly Equation:
- Quantifying Bias Complexity Index: Determining bi for each type of bias could be challenging, as this requires an in-depth understanding of how each bias type manifests and affects the algorithm's outputs.
- Data Requirement: Accurate application of this equation requires extensive data on the algorithm’s outputs to reliably calculate the frequency and complexity of various biases.
- Complementarity: This method should be complemented with qualitative analyses and other bias measurement techniques to ensure a well-rounded understanding of the bias landscape in the algorithm
Calculating the Bias Complexity Index
To compute the bias complexity one needs to multiply balanced distribution of socio-technical factors by numeric index values based on severity of outcomes, then compute an overall index bi through a weighted summation. Below is a how one could compute the socio-technical factors.
Socio factors: User/Target Beneficiary Perspectives
Technical factors: Data science tool perspective
Policy factors: algorithmics life cycle perspective (based on PRIDAR)
Socio factors: User/Target Beneficiary Perspectives
- Decompose by model transparency: Assess how much visibility exists in different model components like data, features, parameters etc. More black boxes = higher bci
- Decompose by model scope: Analyse what functional areas or decision types the model impacts. Highly consequential areas = higher bci.
Technical factors: Data science tool perspective
- Decompose under target representation: Evaluate what populations, contexts and scenarios the training data represents v the target beneficiary. The lower the representation the higher the bci.
- Decompose by data quality: Examine the accuracy, uncertainty, errors, completeness of data and biases in the training data. The poorer data quality and higher bias in the training data introduces likelihood of more hidden biases not corrected through data pre-processing - higher bci.
Policy factors: algorithmics life cycle perspective (based on PRIDAR)
- Decompose user centred design: Evaluate what populations have been involved in user centred design of the training data and algorithm. The lower the representation the higher the bci.
- Decompose organisational assurance and preparedness: Examine compliance to assurance needed in the sector and a algorithmic users readiness to support the algorithm. The less prepared the higher bci.
Techniques for gathering User/Target Beneficiary Perspectives
- risks are best obtained by interviews. In healthcare this would involve interviews with doctors, patients, and other stakeholders to understand real-world impacts of the model’s biases.
- severity of outcomes is best obtained mapping model deployments into real life scenarios e.g. in healthcare this would involve reviewing against actual healthcare pathways.
Techniques for gathering data science tool perspectives
- Individual Fairness: Since LLMs interact with individual users and generate responses based on varying inputs, ensuring that similar inputs lead to similar and fair outputs is crucial. This metric helps in evaluating whether the model treats equivalent inputs in a consistent manner, regardless of potentially sensitive characteristics embedded in those inputs.
- Equality of Opportunity: This is important for ensuring that the model provides accurate and fair outputs across different demographic groups, especially in contexts where the model's output can impact decisions or opportunities afforded to individuals (e.g., job application screenings, loan approvals).
- Equalised Odds: For an LLM, it's vital to ensure that the model's error rates (both false positives and false negatives) are similar across different groups. This is especially critical in applications where incorrect outputs could have significant negative consequences for certain groups.
- Demographic Parity: This metric is useful for assessing whether the overall rate of positive outcomes (e.g., favourable predictions or recommendations) is independent of sensitive attributes like race, gender, etc. While it doesn't consider the underlying distribution of traits in the population, it's a good starting point for identifying potential biases.
- Predictive Parity: Understanding whether the accuracy of the model's predictions is consistent across different groups can be important, especially if the LLM is used for predictive tasks in diverse domains.
- Calibration: This metric is useful if the LLM provides probabilistic outputs. It ensures that the predicted probabilities of outcomes are accurate across different groups. However, in many LLM applications, this might be less directly relevant.
- Disparate Impact: While related to demographic parity, this ratio-based metric is often used in legal and regulatory contexts to ensure compliance with anti-discrimination laws and can be a useful final check.
Techniques for gathering an algorithmic life cycle perspective
These techniques are shown in the PRIDAR part of this web site. They are relate to organisational views on the algorithmic system from
These techniques are shown in the PRIDAR part of this web site. They are relate to organisational views on the algorithmic system from
- User centred design events
- Sandpits where it has been tested
- Compliance, assurance, quality and safety
- The user readiness to support, monitor and govern the systems use
Use of CALMS in Best Practice

In industry this approach is embodied in the custom and practice of suppliers.
Below it could be represented in the Google Med-Palm Process within the following elements:
Below it could be represented in the Google Med-Palm Process within the following elements:
- Model Customisation
- Grounding Service
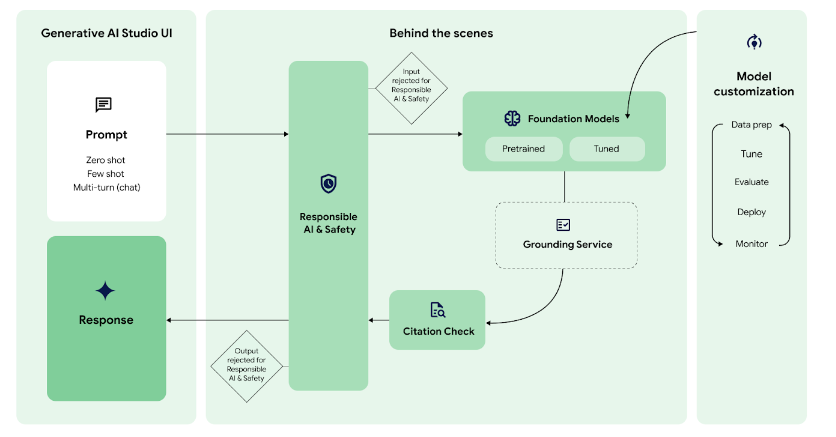
The Google Ped-Palm Process is Copyright Goolge LLC
Foundational Models Bias Effects and Affects
Situation
The use of foundation models like Large Language Models (LLMs), specifically the GPT series, introduces added complexity for bias mitigation due to several inherent characteristics of these models:
Problem
Foundation models like Large Language Models (LLMs), including GPT-series models, introduce added complexity for bias mitigation due to their inherent design and operational characteristics. These complexities give rise to several problems:
Implications
The added complexity in bias mitigation for foundation models like Large Language Models (LLMs), including GPT-series models, due to their inherent design and operational characteristics, has significant implications for both users of these models and those affected by products and services designed using LLMs. Here are some key implications:
The use of foundation models like Large Language Models (LLMs), specifically the GPT series, introduces added complexity for bias mitigation due to several inherent characteristics of these models:
- Scale of Training Data: GPT and similar LLMs are trained on vast amounts of data from the internet. This large-scale data encompasses a wide range of human language, including texts that may contain biases, stereotypes, or offensive language. The sheer volume and diversity of data make it challenging to identify and mitigate all potential sources of bias
- Opaque Decision-Making Process: LLMs, particularly deep neural networks like GPT, are often described as "black boxes" because of their complex and opaque internal decision-making processes. Understanding how a specific input leads to a particular output is difficult, making it challenging to pinpoint the sources of bias within the model.
- Amplification of Existing Biases: Foundation models can inadvertently amplify biases present in the training data. Since these models learn patterns and associations present in the data, any existing societal biases can be reinforced and perpetuated in the model’s outputs.
- Contextual Nuances and Subtleties: GPT and similar models may struggle with understanding and appropriately handling the nuances and subtleties of human language, especially in sensitive contexts. This can lead to biased or inappropriate responses in situations that require a deep understanding of cultural, social, or emotional nuances.
- Generalisation and Overfitting: These models are designed to generalize from the training data, but they might overfit to particular biases or patterns present in the data. Overfitting to biased data can lead to the model producing biased outputs even in situations where such biases are inappropriate.
- Feedback Loops: In interactive applications, biased outputs from the model can influence user responses, creating a feedback loop that further entrenches biases. This is particularly concerning in scenarios where user interactions continuously shape the model's behavior.
- Diversity of Applications: LLMs like GPT are used in a broad range of applications, from text generation to conversation agents. The diverse nature of these applications means that biases can manifest in numerous ways, requiring tailored mitigation strategies for each use case.
- Updating and Maintaining Models: Continuously updating models with new data and addressing biases is a dynamic and ongoing process. As societal norms and language evolve, biases that were previously unaddressed or new ones can emerge, requiring ongoing vigilance and adaptation.
Problem
Foundation models like Large Language Models (LLMs), including GPT-series models, introduce added complexity for bias mitigation due to their inherent design and operational characteristics. These complexities give rise to several problems:
- Amplification of Existing Biases: LLMs are trained on vast, diverse datasets often sourced from the internet, which include a wide spectrum of human discourse. This training data may contain inherent biases, stereotypes, and prejudices prevalent in society. LLMs, due to their design, don't just replicate these biases but can also amplify them, particularly if these biases are prevalent in the training data.
- Difficulty in Identifying and Isolating Bias: The "black box" nature of LLMs makes it challenging to understand how they process inputs and generate outputs. This opacity complicates efforts to identify the specific sources of bias within the model, as it's hard to trace back how the model's internal representations and decisions lead to biased outputs.
- Contextual Misinterpretation: LLMs, while sophisticated in language processing, may still struggle with accurately interpreting and responding to the nuances and contexts of certain topics, particularly those that are culturally or socially sensitive. This can lead to responses that are inappropriate, offensive, or biased, especially in scenarios where a deep understanding of context is crucial.
- Generalisation and Overfitting Risks: LLMs are designed to generalise from the examples they've seen during training. However, this can lead to overfitting to particular patterns in the training data, including biased or unrepresentative ones. This overfitting can result in the model perpetuating and even exaggerating these biases in its outputs.
- Feedback Loops in Interactive Settings: In interactive applications, such as chatbots or virtual assistants, biased responses from the model can influence user behaviour, leading to a feedback loop that reinforces and exacerbates these biases.
- Challenges in Bias Detection and Measurement: Given the complexity and scale of LLMs, detecting and quantifying bias is a significant challenge. Traditional methods for bias measurement may not be effective or feasible, especially considering the diverse range of topics and contexts LLMs can generate content for.
- Adapting to Evolving Social Norms and Language: Language and societal norms are dynamic and continuously evolving. What is considered biased or inappropriate can change over time, making it a moving target for bias mitigation efforts in LLMs.
- Scalability of Mitigation Efforts: Implementing bias mitigation strategies at the scale of LLMs is a daunting task. Given the size of the models and the complexity of their training processes, applying comprehensive and effective mitigation strategies is both resource-intensive and technically challenging.
- Diverse Application Scenarios: LLMs are used across a wide range of applications, each with its unique context and requirements. A one-size-fits-all approach to bias mitigation is ineffective, necessitating tailored strategies for different use cases.
- Ethical and Societal Implications: There are significant ethical considerations in how biases in LLMs impact individuals and groups, especially marginalised communities. Ensuring that bias mitigation strategies are ethically sound and socially responsible is a complex task that goes beyond technical solutions.
Implications
The added complexity in bias mitigation for foundation models like Large Language Models (LLMs), including GPT-series models, due to their inherent design and operational characteristics, has significant implications for both users of these models and those affected by products and services designed using LLMs. Here are some key implications:
- Risk of Perpetuating Societal Biases: Users and affected parties may encounter outputs that reflect or amplify existing societal biases. This can be particularly harmful in applications involving sensitive topics where fairness and impartiality are crucial, such as in hiring tools, loan approval processes, or educational content.
- Impact on Marginalised Groups: LLMs may inadvertently generate content that is insensitive or offensive to certain groups, particularly marginalised communities. This can lead to perpetuation of stereotypes, misrepresentation, and further marginalization.
- Reliability and Trust Concerns: Users may experience a decrease in trust towards LLM-driven products if they frequently encounter biased or inappropriate responses. This can affect the perceived reliability and credibility of these systems.
- Legal and Ethical Challenges: Organisations employing LLMs in their products or services might face legal and ethical challenges, especially if the output of these models leads to discriminatory practices or violates regulations (like GDPR in Europe or the Civil Rights Act in the US).
- Necessity for User Vigilance: Users may need to be more vigilant and critical of the information provided by LLM-driven applications, understanding that these models can produce biased or incorrect outputs.
- Increased Responsibility for Developers: Developers and companies deploying LLMs bear a greater responsibility to continuously monitor and update their models to mitigate biases. They also need to be transparent about the limitations of these models to users.
- Need for Inclusive Training and Design: There is an increased need for diversity and inclusivity in the teams developing and training LLMs, as well as in the data used for training these models, to ensure a wide range of perspectives and reduce biases.
- Potential for Misinformation: In applications like news generation or content creation, there is a risk that biases in LLMs can contribute to the spread of misinformation or slanted narratives, affecting public opinion and discourse.
- Educational Implications: In educational settings, biased content generated by LLMs can lead to skewed learning and understanding, especially on topics related to history, culture, or ethics.
- Impact on User Interaction Patterns: The way users interact with LLM-driven applications may change, with users either trying to "game" the system to get desired outputs or becoming overly reliant on these systems for decision-making.
- Barrier to Global Accessibility: If biases in LLMs are not adequately addressed, these models might be less effective or even harmful when used in diverse cultural and linguistic contexts, creating a barrier to global accessibility and utility.